Experiência de programação de aprendizado de máquina
Objetivos deste capítulo
Tempo estimado de conclusão: 20 minutos a 30 minutos
- Aprenda uma série de fluxo de programação de aprendizado de máquina aproximadamente por meio do problema de classificação que determina o tipo de flor
Introdução
Este texto destina-se a experimentar rapidamente a programação de aprendizado de máquina.
Portanto, por favor, entenda o uso básico e a explicação da biblioteca, que é essencial ao conduzir a análise de dados em Python, como a gramática básica de programação Python e scikit-learn, numpy, pandas, matplotlib.
Vamos começar o aprendizado de máquina no Google Colaboratory!
No primeiro semestre, explicarei como usar o Google Collaboratory (Google Collaboration Leight) que o Google oferece para o aprendizado e a pesquisa em aprendizado de máquina, além de programar Python e programação de aprendizado de máquina posteriormente.
O Google Collaboratory que você usa neste momento é um serviço gratuito que é desnecessáriopara instalação e você pode preparar seu ambiente Python imediatamente.
(Python e Machine Learning Library estão instalados, portanto você não precisa instalar o Python.)
(Python e Machine Learning Library estão instalados, portanto você não precisa instalar o Python.)
O custo é gratuito e o ambiente de CPU e GPU (12 horas uma vez) está disponível, e o que você prepara está disponível apenas com uma Conta do Google.
Para usar o Colaboratory, basta acessar o URL abaixo.
Crie um caderno
Será exibida a tela "Caderno recente". Selecione "Novo caderno de PYTHON 3" na parte inferior esquerda da tela e clique em.
Ou, é o mesmo para "Criar novo bloco de anotações do Python 3" no menu superior esquerdo.
Ou, é o mesmo para "Criar novo bloco de anotações do Python 3" no menu superior esquerdo.



· No caso de "Criar novo caderno do Python 3" no menu superior esquerdo

A tela Colaboratory apareceu?
Agora, há um editor de texto azul claro no lado direito do botão de execução do triângulo de bala, então
escreva o programa lá.
Agora, há um editor de texto azul claro no lado direito do botão de execução do triângulo de bala, então
escreva o programa lá.
Levará algum tempo no início, mas se você esperar um pouco, o resultado será exibido.
A propósito, os cadernos criados automaticamente são salvos no Google Drive.
A propósito, os cadernos criados automaticamente são salvos no Google Drive.
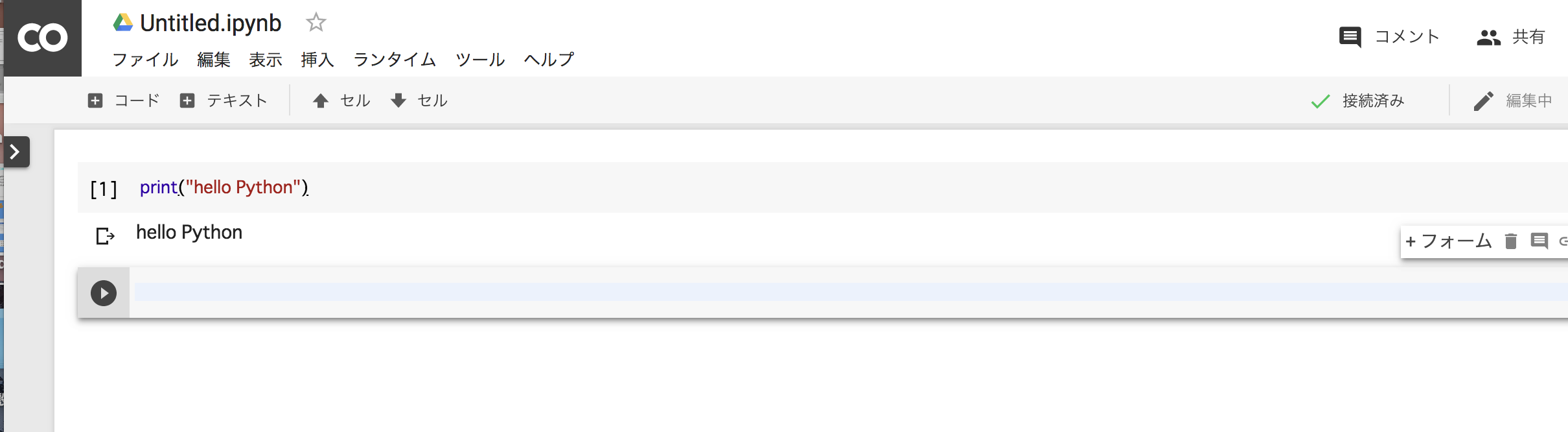
Em seguida, vou desenhar um gráfico usando o módulo de desenho gráfico do Python, Matplotlib.

Tente usar o GPU
Escolha o tempo de execução no menu superior> Alterar tipo de tempo de execução.
Altere o acelerador de hardware de Nenhum para GPU e salve-o.
Altere o acelerador de hardware de Nenhum para GPU e salve-o.


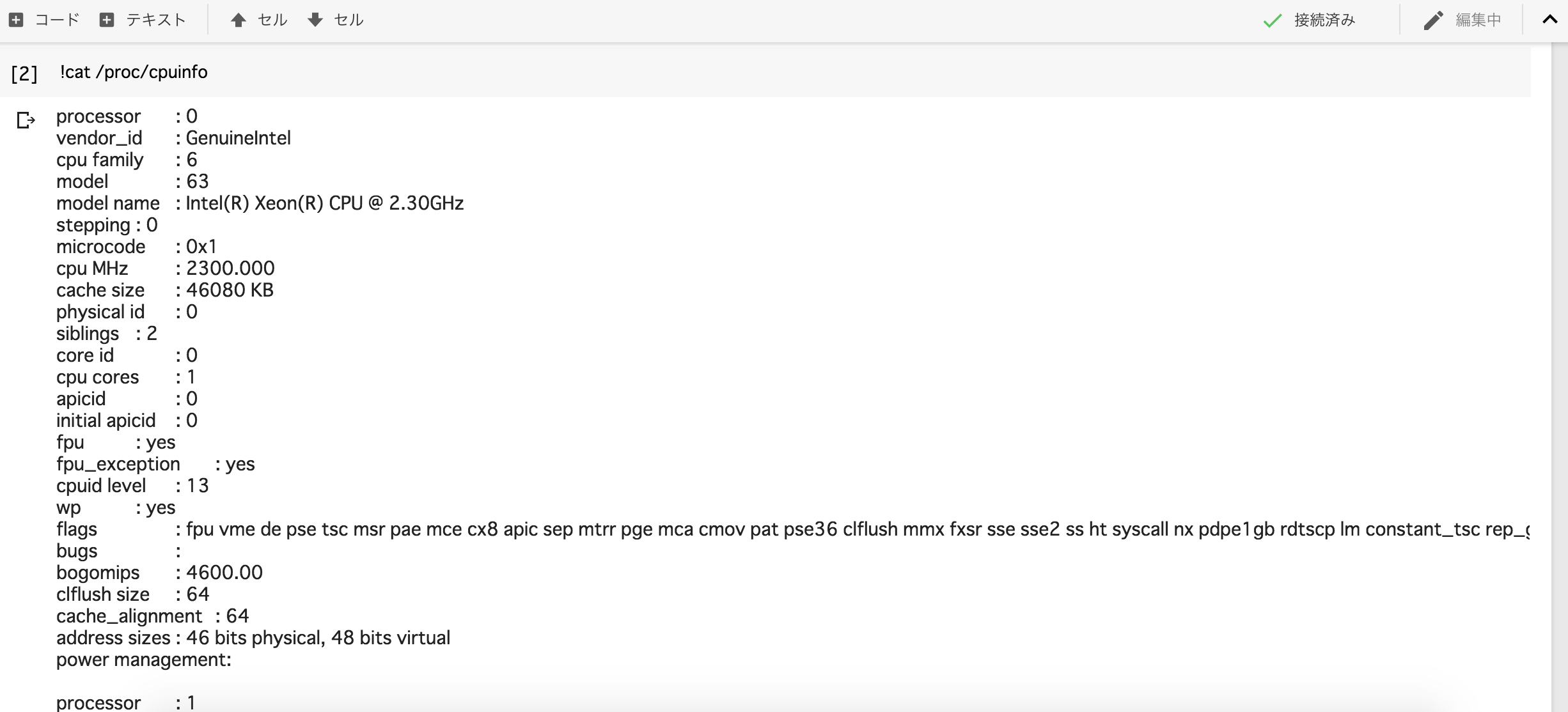
Bem, se você executar o seguinte e saída '/ device: GPU: 0', então você pode usar o GPU.

Além disso,
E
Você pode verificar as especificações da máquina da Colaboratory executando-a.
Experiência de programação de aprendizado de máquina (visão geral)
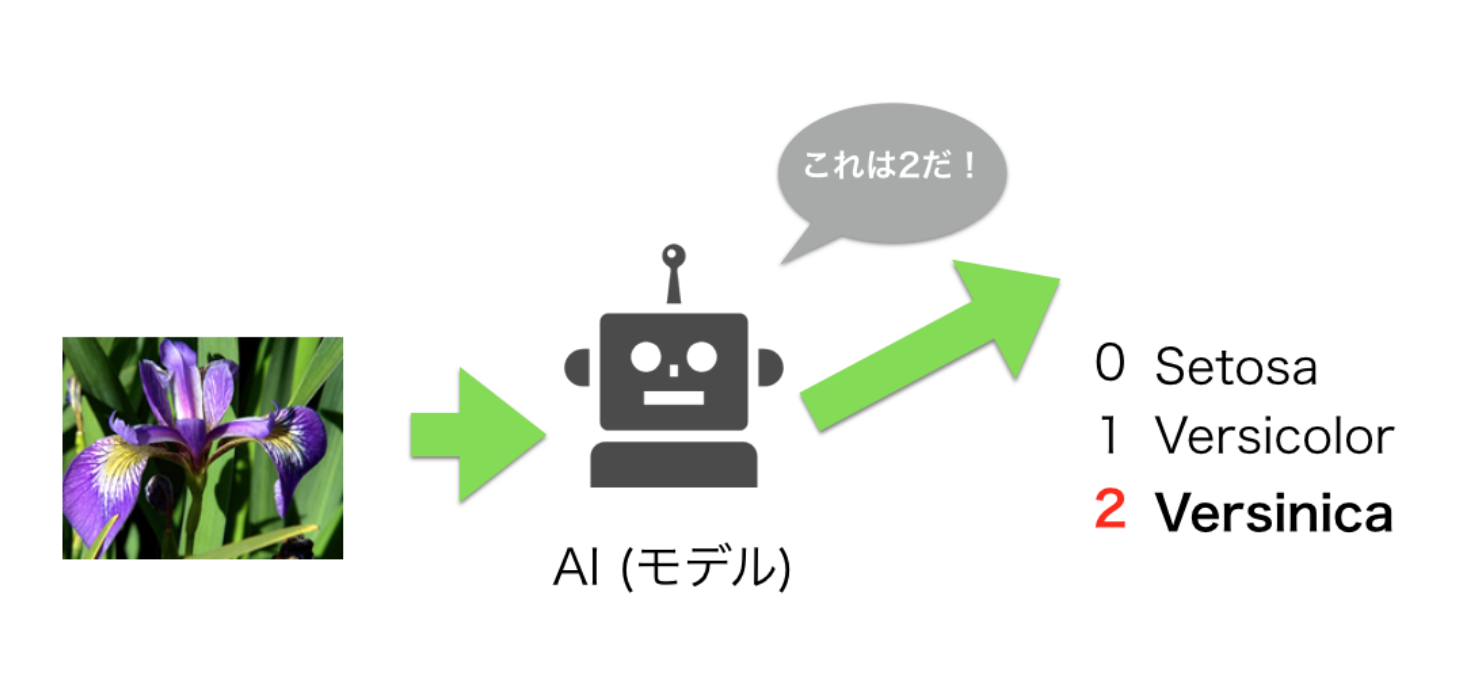
Neste texto vou fazer um classificador que pode determinar o tipo de flor Iris (Iyame).
Como você pode ver na imagem acima, os três tipos são muito semelhantes.
Podemos usar o aprendizado de máquina para classificar variedades de flores.
Podemos usar o aprendizado de máquina para classificar variedades de flores.
Além disso, em cada uma das imagens acima, um rótulo correto de 0 é dado para Setosa (mais à direita), 1 para Versicolor (à esquerda) e 2 para Versinica (centro).
Fonte da imagem: SUPPLITION VECTOR MACHINE (SVM CLASSIFIER) IMPLEMENATION EM PYTHON COM SCIKIT-LEARN
Fonte da imagem: SUPPLITION VECTOR MACHINE (SVM CLASSIFIER) IMPLEMENATION EM PYTHON COM SCIKIT-LEARN
A tarefa de classificar a raça da íris é classificar as variedades de flores a partir do
comprimento e largura das flores, comprimento e largura das pétalas das flores .
comprimento e largura das flores, comprimento e largura das pétalas das flores .
Assim, no conjunto de dados, são dados 150 conjuntos de dados com quatro medidas (características)
ligadas a três flores (SetosalVersicolor, Versinica)
.
ligadas a três flores (SetosalVersicolor, Versinica)
.
| Número | Comprimento · Largura (cm) | Pétala e Sepal |
|---|---|---|
| 1 | Comprimento Sepal | Comprimento do sepal (comprimento dos peixes) |
| 2 | Largura Sépala | A largura do Sepal (o comprimento de uma cola) |
| 3 | Comprimento da pétala | Comprimento da pétala (pétalas) |
| 4 | largura da pétala | Largura da pétala (pétala) |
E o valor de resposta correto (rótulo: nome da flor) é o seguinte.
0: Setosa
1: Versicolor
2: Versinica
0: Setosa
1: Versicolor
2: Versinica
O propósito deste tempo é permitir que uma flor (produção) seja aplicada a qual dos três tipos de flor é aplicável, dadas as variedades de flores (entrada) quando quatro valores medidos são dados (entrada).
Vamos verificar a relação entre entrada e saída novamente.
Por exemplo, os quatro valores de medição a serem inseridos são os seguintes.
Entrada
| Recurso | cm |
|---|---|
| Comprimento Sepal | 1,4 |
| Separar Largura | 3,5 |
| Comprimento da Pétala | 5,1 |
| Largura da Pétala | 0,2 |
Exemplo de programa
Saída
2 (isto é, é julgado como Versinica)
Valor de saída do programa
Experiência de programação de aprendizado de máquina (implementação)
Desta vez, vamos realizar a classificação usando um algoritmo chamado SVM (máquina de vetores de suporte).
Primeiro, do sklearn, o dataset e o SVM da Iris são carregados.
Primeiro, do sklearn, o dataset e o SVM da Iris são carregados.
Em seguida, o conteúdo de dados da Iris e a forma da íris são emitidos.
Como você pode ver, existem 150 dados no Iris.
Em seguida, examinarei o tamanho dos dados.
Em seguida, examinarei o tamanho dos dados.
Agora escreva a máquina de vetores de suporte.
Vamos comentar o processamento da página anterior.
Vamos comentar o processamento da página anterior.
Vamos explicar svm.LinearSVC () e fit () aqui.
Primeiro, o svm.LinearSVC () é um algoritmo chamado SVM (Support Vector Machine).
No scikit-learn, três tipos de SVM relacionados à classificação (SVC, LinearSVC, NuSVC) são preparados.
Vamos usar o LinearSVC nisso. (LinearSVC é um SVM especializado quando o kernel é um kernel linear.)
Primeiro, o svm.LinearSVC () é um algoritmo chamado SVM (Support Vector Machine).
No scikit-learn, três tipos de SVM relacionados à classificação (SVC, LinearSVC, NuSVC) são preparados.
Vamos usar o LinearSVC nisso. (LinearSVC é um SVM especializado quando o kernel é um kernel linear.)
Desta vez vamos classificar a íris usando o algoritmo SVM.
Em seguida, é fit (), mas você pode aprender (aprendizado de máquina) usando fit ().
Damos a quantidade característica X ao primeiro argumento de ajuste () e rotulamos os dados Y para o segundo argumento e o usamos.
Em seguida, é fit (), mas você pode aprender (aprendizado de máquina) usando fit ().
Damos a quantidade característica X ao primeiro argumento de ajuste () e rotulamos os dados Y para o segundo argumento e o usamos.
Em seguida, vamos fazer uma previsão sobre o modelo que fizemos.
O que eu dei é o que a flor é aqueles com comprimento
1,4
largura da testa 1,8
comprimento das pétalas 3,9
largura da pétala 0,5
.
O que eu dei é o que a flor é aqueles com comprimento
1,4
largura da testa 1,8
comprimento das pétalas 3,9
largura da pétala 0,5
.
A saída é uma de 0, 1, 2 (rótulo de flor), mas ao inserir o
comprimento e largura da flor com isso, foi decidido que o rótulo da flor poderia ser previsto.
comprimento e largura da flor com isso, foi decidido que o rótulo da flor poderia ser previsto.
Ao executar o programa até agora, podemos agora classificar a variedade de plantas.
Este é todo o código-fonte até o momento.
Este é todo o código-fonte até o momento.
Resumo
Neste capítulo, usamos o scikit - aprenda a classificar os conjuntos de dados da íris e experimente a programação de aprendizado de máquina.
O tema tratado neste momento é apenas sobre a classificação da aprendizagem supervisionada de aprendizado de máquina.
Além disso, há também regressão, etc, por isso, se você quiser aprender mais , avance o curso introdutório de programação de aprendizado de máquina
O tema tratado neste momento é apenas sobre a classificação da aprendizagem supervisionada de aprendizado de máquina.
Além disso, há também regressão, etc, por isso, se você quiser aprender mais , avance o curso introdutório de programação de aprendizado de máquina
